




Googleがスマートフォンを使い0.5秒で画像生成できるアプローチ「MobileDiffusion」を発表
テキストを基に画像を生成するAIモデルはいくつかありますが、高品質な画像を生成する主要なモデルは何十億ものパラメータを処理するため、基本的には強力なスペックの端末を必要とします。2024年1月31日、Googleのエンジニアらが「MobileDiffusion」というアプローチを発表し、スマートフォンのようなモバイルデバイスでも効率的に画像を生成できる方法を紹介しました。
MobileDiffusion: Rapid text-to-image generation on-device – Google Research Blog
https://blog.research.google/2024/01/mobilediffusion-rapid-text-to-image.html
Stable DiffusionやDALL-Eなどのモデルが進化する一方で、モバイルデバイスで高速に画像を生成する方法はあまり進んでいるとはいえません。特にノイズ除去を繰り返すことで高品質な画像を生成する「サンプリング」などの試行(ステップ)回数が増えると、モバイルデバイスのスペックでは処理しきれないこともあります。先行研究ではこのサンプリングステップを減らすことに焦点が当てられてきたのですが、たとえサンプリングステップが少なくなったとしても、モデルのアーキテクチャが複雑なため、生成に時間がかかることがあるそうです。
そこでGoogleが開発したのが「MobileDiffusion」です。Googleはこれを「モバイルデバイス用に設計された効率的な潜在拡散モデル」と位置づけており、512×512ピクセルの高画質画像をAndroidおよびiOS端末で0.5秒で生成するなど、モバイルデバイスに特化した画像生成モデルに仕上げているとのことです。
以下の画像をクリックすると、モバイルデバイスでリアルタイムに画像を生成している様子を確認できます。

Googleはアーキテクチャの複雑さを解消するためにDiffusionGANを採用することでワンステップのサンプリングを実現。テキストから画像への拡散モデルにおいて極めて重要な役割を担う変換ブロックの効率性を改善するため、ボトルネックでのリソース集約が少ないUViTアーキテクチャのアイデアを採用してUNetアーキテクチャを構築したとのこと。
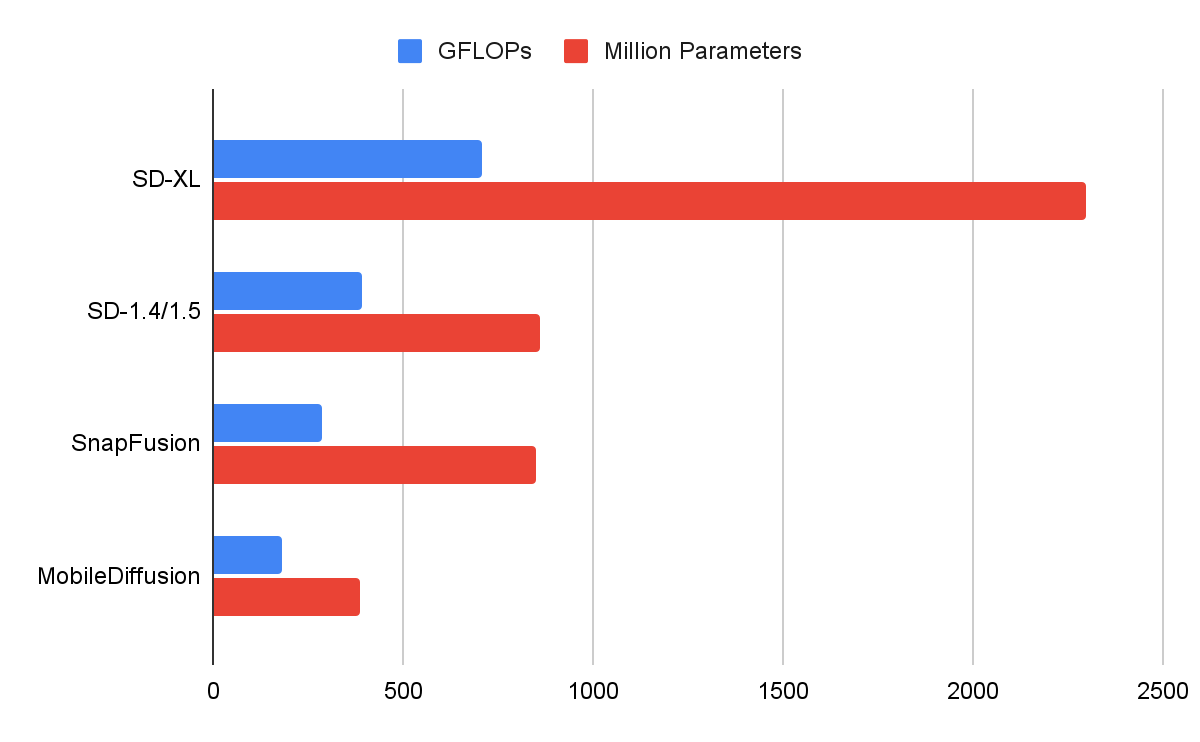
MobileDiffusionのUNetと他のいくつかの拡散モデルのUNetを比較すると以下の画像のようになり、MobileDiffusionはFLOPs(浮動小数点演算)とパラメータ数の点で優れた効率を示しています。またGoogleはUNetに加えて画像デコーダも最適化しており、性能を大幅に向上させ、待ち時間を50%近く短縮したと説明しています。
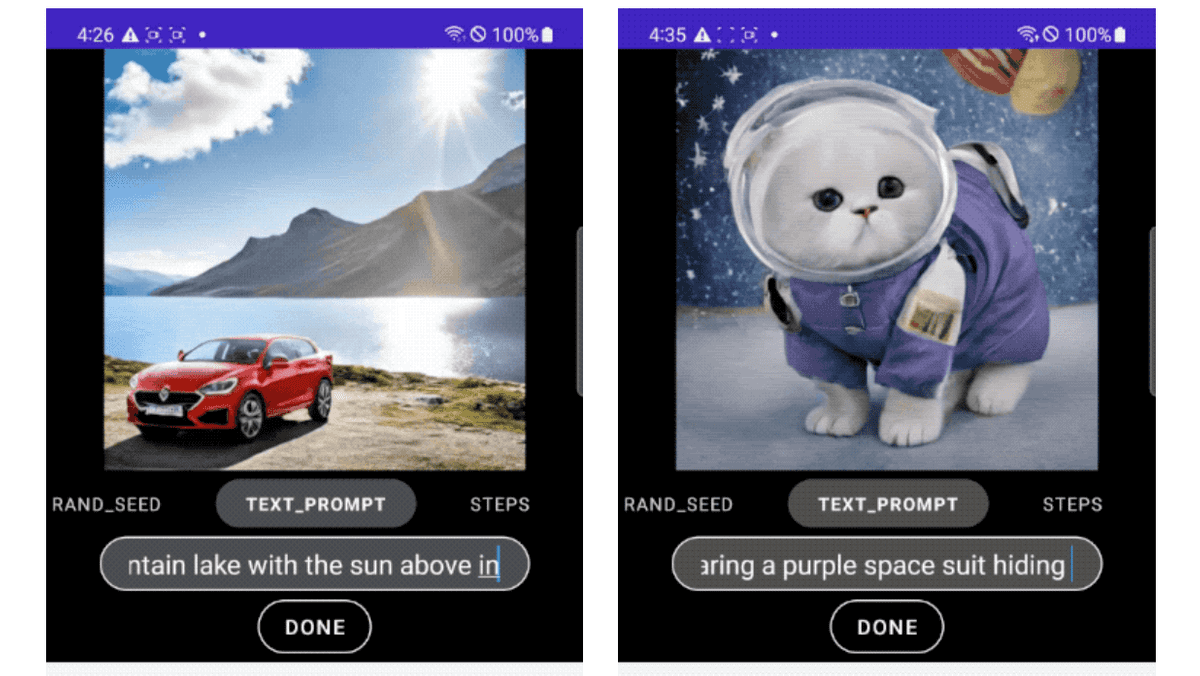
DiffusionGANのワンステップサンプリングにより実現するMobileDiffusionの能力で生み出された画像が以下の通り。最終的にモデルは5億2000万のコンパクトなパラメーター数となり、モバイルデバイスで高品質かつ多様な画像を生成することができたそうです。

・関連記事
SamsungがChatGPTのように会話やコードや画像を生成できる独自のAI「Samsung Gauss」を発表 - GIGAZINE
画像生成AI「Stable Diffusion」でスマホでもわずか1枚2秒という爆速で画像生成ができる「SnapFusion」 - GIGAZINE
画像生成AI「Stable Diffusion」開発元がAI画像編集アプリ「ClipDrop」の開発元を買収しAIアプリ開発体制を強化 - GIGAZINE
・関連コンテンツ






in ソフトウェア, Posted by log1p_kr
You can read the machine translated English article Google announces ``MobileDiffusion'&….